最近在深入研究AI深度爬虫技术,主要是想通过AI技术把我之前写的各种网爬虫代码进行升级,2018年我破解过中文裁判网、专利网、商标网、天x猫、淘x宝、天某查、企某查、启某宝等各种网站各种反爬技,当时为数据分析使用,训练AI模型时候需要用很多数据源,每个网站的数据源都建立一个数据库主要用于做数据分析和训练AI模型使用。
采用的技术是Python的request+selenium+cookie池+代理IP池+分布式+多线程技术来实现这些网站的数据批量采集,我当时每个网站都专门开发了一套专门针对每个网站的爬虫系统把数据爬取存储到本地,然后把数据清洗到数据库,由于采用分布式多进程,几千万数据的采集速度很快,只要运行爬虫就可以实现原始数据采集、数据更新、数据清洗、数据mysql存储、数据查询excel导出,但是现在AI深度学习技术上来了,之前爬虫技术如果接上AI深度学习技术,那么可以实现自动模拟人行为浏览数据、模拟千军万马的真人行为操控浏览器,自动模拟破解验证码、自动采集任何网站反爬都无法阻挡,关于爬虫技术,自己从事爬虫深度挖掘技术有不少的心得,希望能够给其他的朋友分享一些个人的经验和心得。以下从美团网站的数据采集面临的技术和如何快速的得采集到整个网站的数据而且不受限制和封IP做一些技术分享。(需要爬虫技术和数据挖掘交流的朋友欢迎加我qq:2779571288)
我们需要的数据字段:城市名称、星级、酒店名称、酒店地址、评分、联系方式、酒店简介、酒店政策、资质证书。
当我们需要采集每个城市的大批量这些酒店基本信息数据来做某些行业分析的时候,那么美团开放的数据基本可以满足这个需求了,去年有个朋友需要做分析全国每个城市的酒店房间价格、房间数量、房间使用率、酒店服务评价、酒店的星级分布统计等这样的一个行业报告,找到我帮忙。我当时开发了一套美某团数据深度爬虫系统,以省为单位,每个省一张表,然后按城市分类,用了几天时间把全国每个市的酒店基本信息数据全部采集下来,全国有34个省市,34个数据表,每个表存每个省市的酒店数据。然后把这些数据存储到mysql数据库里,以后可以从数据库读出来做分析使用。
一、 破解字体库加密问题:
我们爬一个网站,分析一个网站的技术难度,第一个看技术门槛就是验证码,如果验证码破解不了,那么后面的爬虫工作就无法继续了。解决验证码的方法很简单,我们采用python语言开发的时候,才有python的图像深度识别技术,可以快速轻松解决网站验证密码的问题。
本章我主拿美团网作为技术学习分享案例,,给大伙分享一下如何分析美团网的验证码
目标网站:https://hotel.meituan.com/shanghai/。这个网站,默认大部分数据是公开的(下面拿技术分享仅仅在公开的数据层面进行讨论),只需要酒店关键词、星级、地区点击搜索就可以得到你需要搜索的列表,不用输入验证码就可以直接进入详细页面。然后你获取列表所有的A链接标签hef的值就可以得到所有酒店的详细页面的数据。
只要你能给进入详细页面,那么几乎数据就可以爬取到了。但是这个网站你访问太多的时候回出现验证码,这个是美团网站工程师技术的一个反爬技术之一,如果要绕过验证码,有两种办法,第一种就是接入打码平台,第二种就是采用代理IP池切换IP,我不建议接入打吗,因为打码成本很高,而且正确率很低的。我当时是自己建立了自己的代理IP池,如果同一个IP访问次数超过反爬的最高值出现验证码了就马上切换一个IP,通过不断切换IP来破解出现验证码反爬问题。
二、封掉IP,数据无法爬取的问题:
我在美团网的时候,对IP封得特别厉害,您休想几万或者几十万的去批量采集他里面的数据,这个问题怎么解决呢,其实很简单,我当时自己建立了代理IP池,每次发送一个http请求的时候采用一个动态的IP,这样就非常轻松的解决了爬数据的时候的封IP问题,下面这个就是我自己采用分布式多线程方式采用python+代理IP池结合开发的查爬虫系统的数据管理
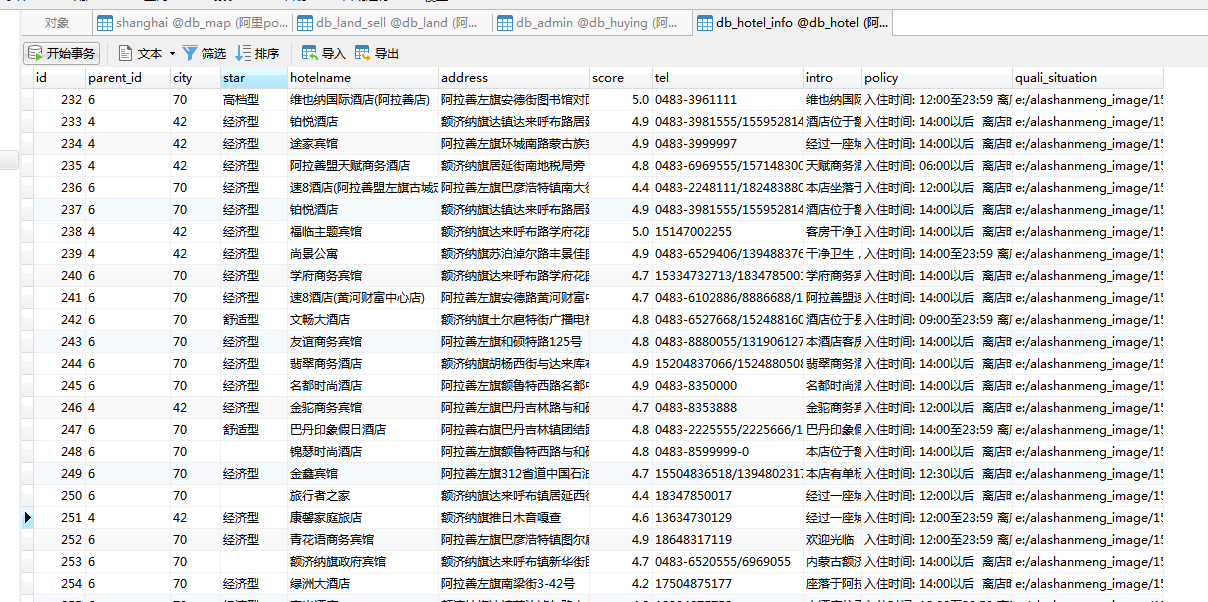
后台

二、数据清洗、数据提炼问题:
在爬数据的时候,会存在重复数据的问题,尤其是像美某团种网站数据的采集,我去年爬的时候整个网站大概有几千万的数据量,越爬到后面就越大,因为每次爬入库的时候都做了对比是否重复,这样导致速度很慢,最后我重新架构的数据库的结构,把数据库分为2个库,第一个库叫做原始数据库,也就是把爬虫从网站爬下的数据先存储到原始数据库,第二个数据库就是 标准库 我写一个数据清洗提炼的机器人,每天从原始数据库读取数据 进行去重分析 把完整的数据清洗提炼到标准库去,那么用户正式使用链接的数据库就是标准完整的不存在重复的数据库,这样爬虫和用户正式分开,性能非常好。下图是我做的爬虫系统的架构分享给大家。
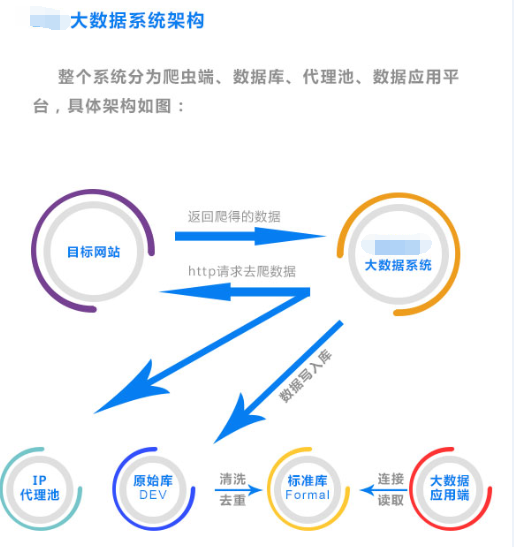
原始库:数据库我们实现读写分离的简易架构,python爬虫不断的把数据采集下来并且写入到原始数据库,写入的时候不用做去重的判断,因为如果您在写入的时候就判断是否存在再去入库,那么当一个表里面有几千万的数据你逐个去匹配去重时候速度是非常慢的,几十分钟你才能成功插入一条新的数据,所以这个时候我们就应该把判断去重的工作交付给异步清洗处理,尽可能让采集新数据的工作压力越小越好,这样采集的速度就很快,爬虫就负责一直采集入库即可。
标准库:我们中间会有一个数据清洗过程,数据清洗其实很简单,就是把原始库的数据异步复制到标准库中,只是在复制插入到标准库的过程中先判断标准库是否已经存在该条数据了,如果存在就更新之前没有的字段,如果不存在就直接插入库一条。
数据清洗:我们一程序实现数据库复制和判断去重的,把原始库的数据复制一份到标准库后,立刻把原始库的意见清洗过的数据删除掉,为什么需要删除掉原始库已经清洗过的数据呢?因为如果不擅长,那么原始库越来越大,以后每次清洗数据量越来越大而且都是重复清洗,导致清洗工作重复和压力大。
代理IP池:也许您会问这个代理IP池是做什么,又是怎么实现的呢?我们在爬网站的时候,需要用代理ip不能用我们自己电脑的IP去爬,原因是在你电脑直接运行代码那么爬虫的IP就是你电脑的IP ,如果一直频繁的去采集对方的网站,那么对方会检测到您的IP直接把您的IP列入黑名单导致你以后在也采集不了了。所以我所有的批量采集爬虫都采用代理IP去爬的,python怎么采用代理IP呢?其实很简单就那么一行代码就解决:
resp = requests.get(url, headers=self.headers, timeout=20, proxies=proxy)
我们调用的是requests的get方法 里面有url、和headers以及 , proxies代理IP设置的参数。
url:就是我们采集的目标网站地址
headers:就是我们模拟访问对方网站时候需要模拟的头参数(这个参数怎么来呢,其实很简单,直接用火狐打开对方网站查看网络里面有和请求头那些参数复制过来即可)
Proxies:就是我们的设置我们的代理IP,代理IP是什么意思呢?代理服务器的工作机制很象我们生活中常常提及的代理商,假设你的机器为A机,你想获得的数据由B机提供,代理服务器为C机,那么具体的连接过程是这样的。 首先,A它与C机建立连接把请求发给C,C机接收到A机的数据请求后马上与B机建立连接,下载A机所请求的B机上的数据到本地,再将此数据发送至A机,完成代理任务。这样下载对方网站的数据的是代理服务器,而这个代理服务器IP是随机变动,对方就抓不到是谁一直采集他的数据了。那这个代理ip我们清楚了,这个ip代理池又是什么呢?我们运行我们的python程序的时候,每秒发一个http请求去爬对方网站一次,请求一次需要一个IP,那么这个ip怎么来呢?我们可以网上购买第三方那种ip接口,比如:每10秒中会返回1个IP给我们用,如果我们每次爬数据都先要调取代理IP接口得到IP了再去爬对方网站 那么这个效率和代码质量就低了,因为人家是10秒中才一个IP,您的程序速度和效率就直接卡在因为代理IP接口控制问题了,所以这个时候您需要改进代理IP代码架构,首先每10秒中读取代理IP接口得到的IP 缓存到reis去,并且设置60秒过期,那么这个redis就会形成一个代理IP池了,您的程序代码爬对方网站时候直接从redis读取IP去爬,这样速度就快了,程序架构就优化了。
今天时间不多了,先分享到这里,
最近我一直从事大数据挖掘技术研发和AI研发,曾经通过网络神经技术研发了数据挖掘AI模型,采用网络数据挖掘技术开发了天某查企、中文裁判文书网、专利网的数据深度挖掘系统,采用分布式+集群技术实现千万级的数据深度挖掘,最近在深入探究健康医疗、土地交易、酒店、地图等领域数据深度挖掘技术研究,欢迎广大对大数据和AI技术感兴趣的朋友,欢迎加我q:2779571288交流!